
撰文 / 吴甘沙(驭势科技联合创始人、董事长兼CEO)
编辑 / 涂彦平
设计 / 赵昊然
Editor's notes
编者按
6月15日,第十六届中国汽车蓝皮书论坛进行到第二天,在当天下午的智能驾驶专场,驭势科技联合创始人、董事长兼CEO吴甘沙带来《面对或然的大模型ChatGPT时刻,自动驾驶创业公司如何应对》的主题演讲。
他提出,“也许大模型是真正的自动驾驶的终局。”马斯克说特斯拉的12.4版本性能提升5倍到10倍。这是否意味着它在模型的规模上有了一次巨大的提升?数十亿到百亿参数的多模态模型是否会出现涌现能力?
吴甘沙表示,“如果特斯拉失败了,就是百亿美金的投资之后还是没有收敛,它的FSD增长曲线到了一定程度开始走平的话,它可能面临着股市的惊天压力。但是如果它成功了,也许这个赛道上的大小公司会被甩开。”
他在演讲中谈到了作为自动驾驶创业公司,驭势科技的应对策略。
以下是吴甘沙的演讲实录,有删减。

非常感谢汽车商业评论的邀请,很高兴再次来到蓝皮书论坛。各位同行,各位媒体朋友,大家好。因为时间关系,我只讲两个问题:第一,大家说今天我们面临着大模型自动驾驶的ChatGPT时刻,它会不会发生;第二,作为自动驾驶的创业性公司,该如何应对。
ChatGPT时刻来了?
我们是不是真的面临这样的ChatGPT时刻?
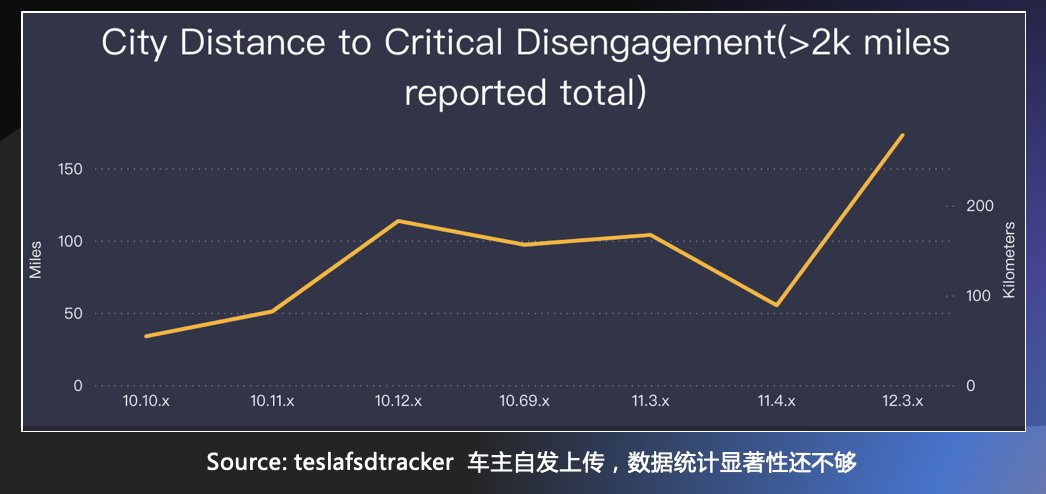
这是特斯拉车主自发上传数据的一个统计曲线。这是一个城市FSD的数据,在11.4到12.3之间出现了一个快速提升的现象。当然这个数据随时在变化,但是基本上200多公里才会有一次“危险接管”。
我们看看国内,国内比较领先的小鹏。何小鹏说得比较实诚,高速上能够达到1000公里1次接管,城市里还不到10公里1次接管。
大家这么初看,感觉特斯拉确实是在快速地拉开差距,但是我们再仔细看一下,看它的12.3.6,其实它的一般接管是31公里1次接管,高速是134公里1次接管。
一方面我们能够看到它在快速地提升,但是如果我们区分危险接管和普通接管,会发现它普通接管的数据也不是遥遥领先。更何况,中国的路况要比美国复杂很多。
大家可以看看2015年的数据,每10万辆车每年导致多少条人命,中国其实是远远超过美国和德国,也就是说中国的交通路况复杂很多。你对比31公里一次接管和不到10公里一次接管,也并没有说特斯拉就是遥遥领先于小鹏。
所以,到目前为止,我们认为可能没有办法得出很准确的结论,除非我们今天看到新闻说特斯拉10台FSD的车要在上海跑了,那这样才能够避免关公战秦琼的这样一种比较。
那为什么我们还是要问这个问题,就是它是不是面临着一个突破的时刻呢?因为我们最近看到马斯克的一些面向投资人的说法:
第一,在过去这两年当中他们的算力提升了10倍以上,提升了一个数量级,从前面5760张A100的Dojo,到今年年底可能会增加到8.5万张的H100。这可是上百亿美元的投资。
第二,训练数据提升了10倍以上。因为Dojo刚刚开始的时候是100万个10秒的视频,但是最近一次接受采访已经达到了几千万个视频。
第三,车端算力差不多提升了5倍,从144TOPS的HW3.0(这个HW3.0只能够跑1亿上下的参数)到现在720TOPS 的HW4.0,而且针对Transformer做了特殊的优化。
所以,我们不由得猜想它是不是在模型的规模上有了一次巨大的提升?从今天的1亿参数到几十亿的参数,它会不会出现涌现能力(举一反三,触类旁通等)?这是我们现在特别期待要看到的。
马斯克在5月份预告了一下,说他们的12.4版本能够提升5倍到10倍。所以,结合这边的这些数据,就是训练算力提升10倍、数据提升10倍,模型提升10倍,性能变成了10倍。所以,这个真正发生是非常有意思的。
而且,我们对比一下大模型的训练,比如前面是10万亿个token,几万张卡训练100天,做预训练,再做有专家监督下的精调(Supervised Fine Tuning),最后是人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)。
这样的例子跟我们人学开车特别类似。我们人学开车前面也有一个预训练的过程,前面18年没有学开车,只是学常识,形成了我的世界观,我的认知模型。这是18年的社会阅历,就像一个预训练的过程。然后到了18岁,我就去驾校找了一个教练来教我怎么开车,这又像专家监督下的Fine Tuning。然后我拿了驾照自己买了车,我从新手上路边开边练,磕磕碰碰,熟能生巧,慢慢地就开得越来越好了。这又像不断反馈下一个强化学习的过程。
所以,也许大模型是真正的自动驾驶的终局。我们今天说的那么多的corner case可能并不是最终靠人力来去穷尽,而是靠这样的一种方法来去穷尽。

2017年我跟旭东(Momenta CEO曹旭东)参加CVPR会议的时候,我们也在谈端到端。当时我就有一个想法,大模型就像我们的系统2,针对一些最难、少见交通状况,需要高算力、高功耗去思考,最后去解决。但是端到端像系统1,它可以类比我们人类驾驶的本能模式。我们今天绝大多数时间开车都是脑子里想着其他的事,听着音乐,以一种极低功耗、极低算力的方式开车,这是端到端的模式。不排除这个可能是我们未来自动驾驶实现的终局的一种模式。
当然如果特斯拉失败了,就是百亿美金的投资之后还是没有收敛,它的FSD增长曲线到了一定程度开始走平的话,它可能面临着股市的惊天压力,因为毕竟一年卖个200万台车可能不值那么高的估值。但是如果它成功了呢,也许这个赛道上的大小公司会被甩开。这个可能是我们下面要拭目以待的。

差异化竞争
我们是以L4商用车为主的一家公司,但是从2016年成立以来,我们一直有一支团队在做乘用车。当然这个团队的规模很小,刚才旭东说1300个人,我们不到十分之一。这么小的团队,我们该怎么做乘用车,今天也跟大家做一个分享。
像FSD这样的投资烈度毫无疑问我们没有办法去做,所以我们做差异化竞争,去对标EAP,做出来极致的智价比。比如我们在10万元的车上面能不能做到EAP。

什么是EAP?大家可以看到特斯拉的智驾就是三个级别,最上面的就是基础版AP,中间那个是EAP,下面是FSD。这个EAP就是我们经常说的高速NOA,行泊一体,它的报价要到32000元,而FSD是64000元。
今天的FSD或者城市NOA是在从90分到99分的过程当中,这里面需要巨大的投资。但是另一方面,EAP这32000元钱的东西,高速的NOA、行泊一体再加上通勤记忆行车,可能在99分到99.99分的过程当中。那么能不能把这套系统做到3000元钱而不是32000元钱?这可能又是一个值得去探索的地方。
就是一方面把体验从99分做到99.99分,另一方面要把成本极大地降低。我们在这里面也有一定的探索。
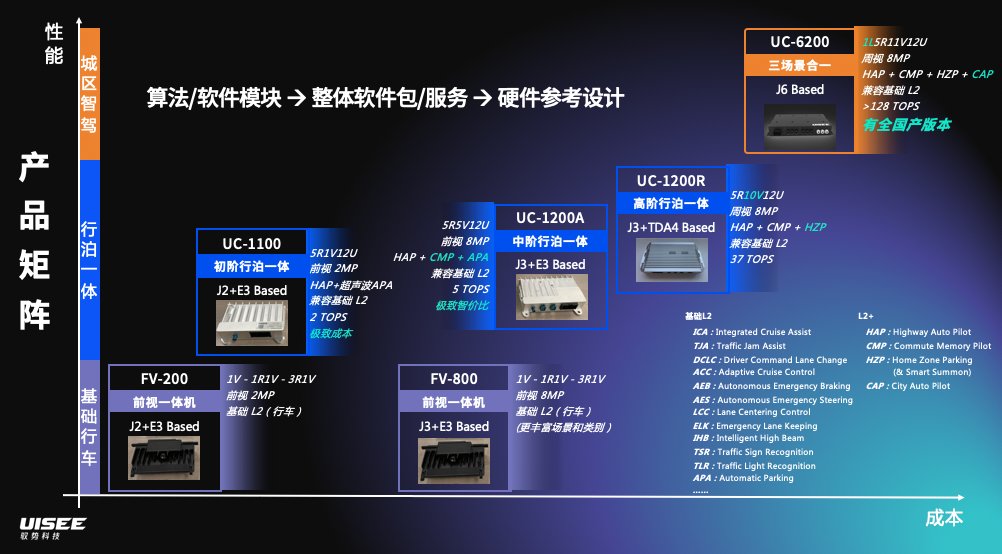
这是我们乘用车的一条产品线,最底端就是一体机。一体机这条产品线基本上都是基于地平线的,底端就是J2的,200万像素、800万像素。我刚才说的就是中间的产品,行泊一体。上面其实是L4跟城市NOA一起想要去构想的预控制器的形态。
中间有一个产品,成本是极低极低的,它是J2再加上E3,能够实现高速的NOA再加上基于超声波雷达的APA,就是一个基本的行泊一体,它是极致的成本。
再往上这是J3再加上E3,我们把它叫做“极致的智价比”,它在这个基础上加上一个融合的APA,另外再加上一个记忆行车。然后在这个基础上又有一个变种,中间再加上TDA4,这里面就是高速领航加上记忆行车之外,再加上记忆泊车。然后再到上面,就再加上城市NOA。这是这么一个产品线。
但是我们采用极高模块复用的设计方法,这样使得我们跟主机厂和Tier1合作的时候可以有非常灵活的身段。可以提供算法或者软件模块,可以提供整体的软件包和服务,也可以把硬件的参考设计给我们的合作伙伴,或者提供软硬件一体的方案,所以,它可以非常灵活。我们基础版的行泊一体和极致智价比的行泊一体,这两个产品都是在小几千块钱,但是能够提供对标EAP的一种体验。
在这个过程中我也介绍一下我们的方法论。其实我们最早对这个团队的要求就是模块化,软件高度模块化可复用,硬件可以支持各类的计算平台,从J3到TDA到恩智浦到英飞凌,包括我们国产的芯驰等等。总结一下,就是硬件能够适配各类的品牌,软件高度模块化。
但是我们前七年基本上是两条路线,就是行车和泊车都是分开去做的。然后就做了这么一个行泊一体的软件架构,这是整个重新开始架构的产品。这个产品我们也是基于SOA,进一步提升开发效率和功能的可扩展性。
同时,我们还做了很多的工作。这里我介绍一点。
因为像这样极致智价比的平台,一个J3再加上一个E3,它除了感知能够用神经网络,其他的很难用数据驱动的方法,很难用神经网络。但是如果今天基于人的规则的这种方法,其实有很多数据没什么用,因为人来不及处理,所以就会利用效率低。但是如果你运用数据驱动的方法,用神经网络,它的安全等级又比较低,它只能达到QM,没有办法达到更高的安全等级。
Joseph Sifakis这位老兄也是图灵奖获得者,他其实问了一个问题,为什么自动驾驶的车那么难?讨论讨论着最终还是走向一个方向,就是基于模型、基于规则,再加上数据驱动神经网络的方法进行糅合,这样的方法能不能在极其低端的芯片上跑起来。

我们拿目标选择作为一个案例,大家可以看到我们在一个MCU上面能够跑出来这么一套系统,一方面它是一个基于数据驱动的LSTM(Long Short Term Memory,长短期记忆)的网络,另一方面是基于规则,再加上一个synthersizer,这么一套系统。神经网络能跑在一个MCU的core上面,然后规则和synthesizer跑在另外一个core上面。当然神经网络的是QM,另外一个是rule-based,是ASIL D。
这些融合起来我们能够综合达到ASIL D功能安全等级。同时,它对代码空间、数据空间的占用,其实是在几百kb的级别,能够达到26262的认证。
我们能不能通过一套融合的系统,一方面满足数据驱动,满足更高的性能,另外一方面又是极致的成本,并满足SOD的要求。
另外的案例,我们通过生成性对抗网络,比如在数据选择、在规控这些今天我们的数据不是特别多的情况下,能够不断地通过生成性的对抗网络来生成更高质量的数据。
这里举一个案例,就是很小的神经网络的算法和基于规则的方式进行融合,那它要去处理的就是一辆车,它在cut-in。大家可以看到基于小神经网络的能够比基于规则提前2秒多就能发现cut-in的意图。总的来说能够大幅减少假阴性,另外把recall可以提升50%。
这套系统我们也用在了很多其他的功能上,比如,这是一个纯视觉的AEB,我们也是拿到了五星+的标准,能够实现85公里时速的一个刹停。

跟随第一梯队
我们还是要紧跟第一梯队,在算法上紧跟前沿,并且还是能够保证可模块化交付。
过去这几年,特斯拉在BEV Transformer,包括像这种无图的Lanes Network,包括从单帧到一个视频流,包括到Occupancy Network(占用网络)等等方面有了很多创新,下一步做各个不同模块的神经网络化,最后实现整体的端到端大一统的网络。
在这些算法方面我们也一直在跟随,像BEV+Transformer+ Occupancy Network这样的网络,我们做的一套系统,最近在一个国际会议Robo Drive Challenge上面拿到了第一名。我们有很多这样的算法,它从这个性能上面看还是非常不错的,这些算法我们都可以把它们作为模块来进行交付。

为大客户服务
创业公司没有办法投入那么多的GPU,也没有那么多的数据,但是谁有?我们的大客户可能有,尤其是一些大的OEM,有数据,也有算力。我们也可以为他们提供像数据闭环、运维平台、大算力训练平台的软件服务。
因为我们做L4,大家知道L4其实需要特别好的闭环,因为它需要快速地迭代。所以,我们在车端有一套黑匣子的数据储存系统(DSSAD),在云端也有一套不错的自动驾驶的训练平台。
特别是从去年开始,我们也在把一些大模型的技术应用进去,场景理解、预标注、数据挖掘等大模型。这是一个典型的做智驾公司或者是OEM该有的平台。那么我们可以做这种云端的container的交付,也可以做实际的一体机的交付。因为可能有些公司并不希望用云,而且它的数据量可能像这么一个24-192卡的一体机,就够用了,那么我们也可以交付这样的一体机,确保快速地部署,落地即用。这是第一点。
第二是我们的运维平台。运维平台我觉得比较有特色。为什么?L4的系统我们是比较早去尝试订阅服务的模式的。就是我卖了这么一个系统以后,因为这个系统里面加了一个AI司机,我每年针对AI司机能够收一点工资,这就是一个订阅服务。
但是这个订阅服务如果你做得不好,其实一方面你没有办法保障客户的满意度。假设说一辆车一天工作20个小时,24小时当中只有4个小时在检修,20个小时99.99%的可用率,也就是一年只有差不多一个小时是没有在工作状态,这个要求非常高。
另一方面,像L4的系统,比如一个激光雷达可能就几万块钱,一个域控又几万块钱,那一年的订阅费可能也就是几万块钱。如果说你不能有很好的一种运维平台,那你订阅服务的这种模式最终是会亏钱的。所以,我们做了一个很好的云服务平台,这样的运维的能力也是可以输出的。

最终做一个总结,我们这么一个小团队应该怎么去做乘用车的智驾。
第一,我们身段非常灵活,可以提供硬件参考设计、整体软件包,或者是单个模块的算法或者软件,或者,我们没有数据和没有算力,我们可以为有数据和算力的客户提供数据/云端服务。
第二,我们也有非常好的算法,一直在紧跟特斯拉的SOTA算法。我们可以模块化交付我们的算法模块,也可以交付整体的软硬件一体的产品,或者是软件包再加上硬件的参考设计。
这个产品我们就聚焦在EAP这种高速NOA再加上行泊一体,再加上记忆行车的这样一种形态上。这样的形态我们希望做到极致的智价比,能够下沉到10万块钱的平台,我们可以支持Tier1或者OEM把这样的产品打造出来。
这就是我分享的内容,谢谢大家!
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com